A API de Processamento em Lote foi desenvolvida para atender à necessidade de realizar consultas em grande escala de forma simplificada e eficiente. Ela permite a execução de consultas em massa para um conjunto de registros, como no caso de enriquecimento de dados ou validação de listas.
Por meio do envio de um arquivo de entrada contendo os registros, a API processa as consultas de forma paralelizada, otimizando o tempo de resposta e oferecendo uma solução ágil para o processamento em lote.
Sobre o Serviço
A maior parte das requisições realizadas contra a Plataforma de Dados segue o modelo tradicional de API, em que uma requisição é realizada por vez. Em algumas situações, no entanto, é necessário um mecanismo que permita executar a mesma consulta, de forma simplificada, para uma grande quantidade de registros.
Esses cenários incluem, por exemplo, o enriquecimento de uma base de dados existente, a validação de uma lista de e-mails ou qualquer outro processo que demande um processamento em lote.
Para atender a essas situações, foi desenvolvida a API de Processamento em Lote, que permite a execução de consultas para registros contidos em um arquivo de entrada submetido pelo cliente, processando as consultas de forma paralelizada para minimizar o tempo de resposta.
Nessa API, ao invés de realizar a chamada e aguardar o retorno imediato, o cliente submete um lote (batch) de registros, com algumas configurações iniciais, e é avisado posteriormente quando o processamento for finalizado. Além da submissão de um lote para execução, é possível pausar, cancelar ou reexecutar um processamento já existente.
Iniciando o processamento em lote
Para oferecer maior versatilidade aos clientes, existem diferentes formas de utilização da API de Processamento em Lote, cada uma adequada a fluxos distintos. Independentemente do fluxo escolhido, todas as execuções partem da mesma etapa inicial: a definição dos datasets e parâmetros que serão processados.
Nesse método é necessário enviar as configurações iniciais para a consulta de um lote de registros: o arquivo com os registros que devem ser processados, a API que deve ser consultada, o formato do arquivo de saída e algumas informações de metadados do arquivo de entrada, como indicado pelo exemplo abaixo:
POST: https://plataforma.bigdatacorp.com.br/lote/salvarDefinicao
{
"InputFileUrl": "web{https://www.example.com/mysamplefile.txt}",
"InputKeysHeader": "Documento",
"APIName": "people",
"Datasets": "basic_data",
"QueryTemplate": "doc{{0}}"
}A partir dessas informações, conseguimos identificar que é necessário consultar os Dados Básicos na API de Pessoas, usando a primeira coluna que é chamada de "Documento". Como resultado, o método retorna um código e mensagem de erro, caso algum problema tenha ocorrido. Do contrário, é retornado o identificador único do job(JobId), que pode ser utilizado para recuperar outras informações sobre o mesmo ou cancelar sua execução (veja os outros métodos da API de Processamento em Lote).
Após a definição das configurações necessárias para o job, os documentos são preparados internamente para a consulta. Quando esse processo é concluído, o status do job é alterado para loaded, e o cliente é notificado por e-mail de que a carga dos registros para processamento foi finalizada.
AtençãoEsse passo não é necessário, caso você já tenha definido o parâmetro AutomaticallyStartQuerying como true em Salvar Definição.
A partir desse momento, o job está pronto para iniciar as consultas. Para dar continuidade, o cliente deve fornecer o JobId correspondente a esse processamento, conforme descrito abaixo:
POST: https://plataforma.bigdatacorp.com.br/lote/iniciarExecucao
{
"JobId": "[IDENTIFICADOR ÚNICO DO JOB]"
}Endpoints da API
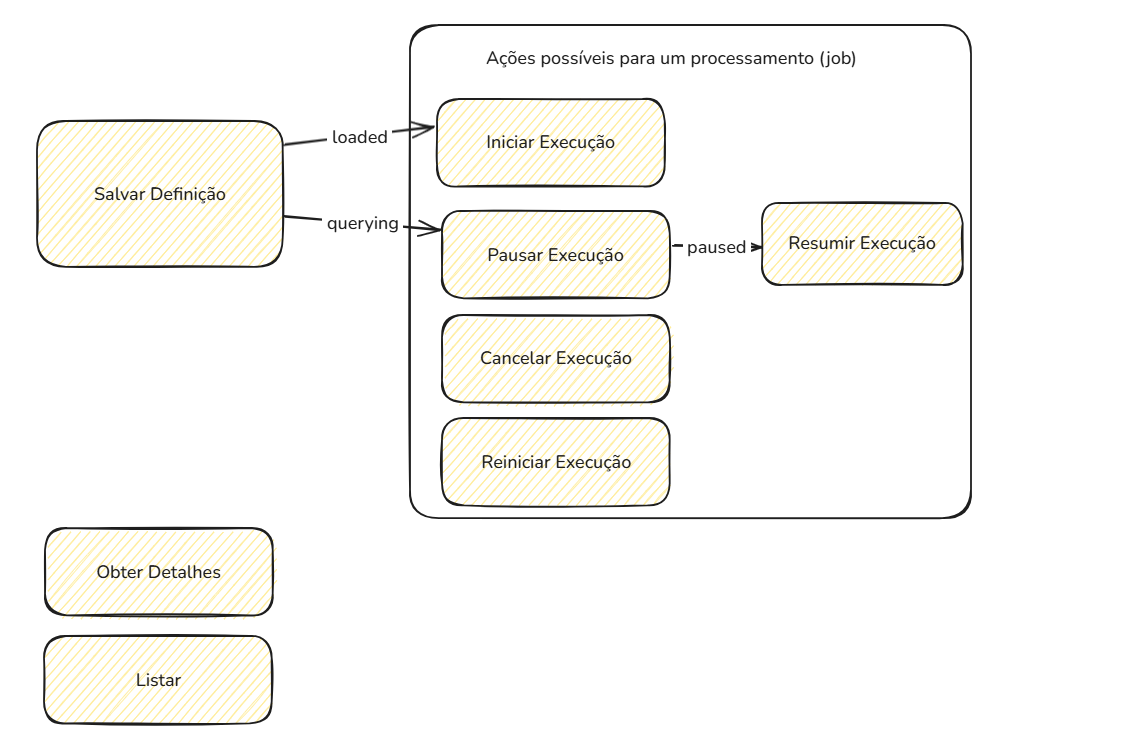
A seguir serão descritos as funcionalidades disponíveis para uso na API de Processamento em Lote. Para obter mais detalhes sobre cada uma, acesse suas respectivas páginas de documentação.
Este método permite ao usuário recuperar a lista de processamentos em batch solicitados pelo mesmo, com dados detalhados sobre cada um dos processos.
Este método permite ao usuário recuperar informações detalhadas sobre o progresso de execução de qualquer job que tenha sido submetido para execução. A partir do identificador do job (JobId) que deseja consultar.
Esse método permite ao usuário suspender a execução de um job que está sendo processado, a partir do identificador do job (JobId) do mesmo.
Este método permite ao usuário retomar a execução de um job que foi suspendido, a partir do identificador do job (JobId) do mesmo.
Esse método permite ao usuário cancelar a execução de um job que está sendo processado, a partir do identificador do job (JobId) do mesmo.
Este método permite ao usuário reexecutar todas as etapas de um job, a partir do identificador do job (JobId) do mesmo.
AtençãoTodos os resultados obtidos até então serão perdidos e todas as consultas serão reexecutadas, e sendo cobradas novamente.
Cobrança
Cada consulta realizada em um dataset no processamento em lote possui o mesmo custo de uma requisição padrão. O valor final de um processamento é multiplicado pelo número de registros que foram consultados.
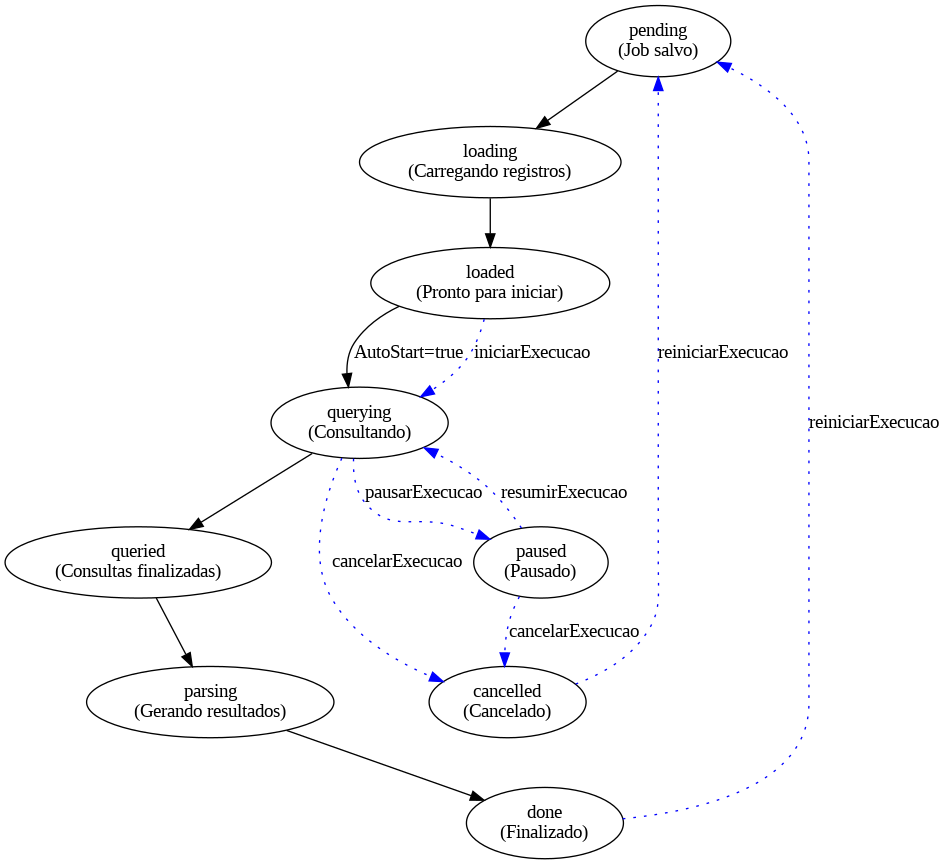
Fluxograma da API de Processamento em Lote
A seguir, explicamos cada etapa do fluxo:
🧾 1. Salvar Definição
O primeiro passo do processo é o envio da definição do job, que configura como o lote de dados será processado.
Resultado esperado: retorno de um JobId (identificador único do job), que será usado nas próximas etapas.
Status inicial: pending
🔄 2. Carregamento dos Registros
Após salvar a definição, o sistema carrega o arquivo com os registros para preparar as consultas.
Status alterado para: loading
Ao final do carregamento:
Status: loaded
O sistema notifica o usuário por e-mail.
A partir deste ponto, o job está pronto para iniciar as consultas caso o parâmetro AutomaticallyStartQuerying não tenha sido definido como true.
▶️ 3. Iniciar Execução
Se o job estiver em estado loaded, o usuário deve iniciar a execução manualmente (caso não tenha sido automático)
Status alterado para: querying
⏸️ 4. Controle da Execução (opcional)
Durante a execução, o usuário pode controlar o andamento do job:
- Pausar execução: Status vai para
paused - Resumir execução: Retoma para
querying - Cancelar execução: Finaliza o job com status
cancelled - Reiniciar execução: Recomeça desde o início com base na definição original
📥 5. Finalização das Consultas
Depois que todas as consultas forem executadas:
Status: queried
Em seguida, o sistema inicia o processo de parseamento dos dados.
📦 6. Geração do Arquivo de Saída
O sistema transforma os dados obtidos em um arquivo de saída no formato especificado.
Status: parsing
✅ 7. Conclusão
Quando o parseamento é finalizado e o arquivo de resultado é gerado e enviado:
Status final: done
Resumo dos Status
| Status | Descrição |
|---|---|
pending | Job salvo, aguardando processamento |
loading | Arquivo sendo carregado |
loaded | Pronto para iniciar consultas |
querying | Consultas em andamento |
paused | Execução pausada |
queried | Consultas finalizadas |
parsing | Resultados sendo processados |
done | Job concluído com sucesso |
cancelled | Job cancelado pelo usuário |